Examples and use cases
Export/Import Dump:You can copy a data base to a special ZIP/JAR file. Afterwards you can use this file to import the data into some real data base.
This is realized via special connectors. You could however implement your own dump format, too.
One cool feature is that you can specify a class that is used as the value of the Main-Class: attribute in the META-INF/MANIFEST.MF of the generated JAR file. I.e. you can execute the JAR file using your own code. By default, a simple viewer will be started.
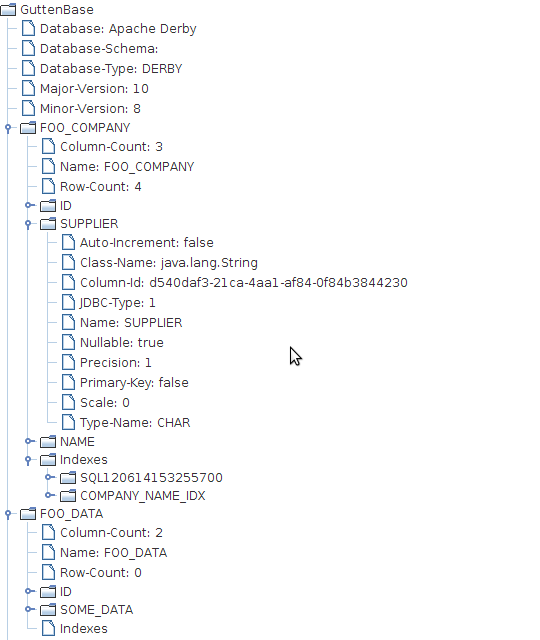{kind=link}
...
_connectorRepository.addConnectionInfo(CONNECTOR_ID1, new MySqlConnectionInfo());
_connectorRepository.addConnectionInfo(CONNECTOR_ID2, new PostgresqlConnectionInfo());
_connectorRepository.addConnectionInfo(EXPORT, new ExportDumpConnectorInfo(CONNECTOR_ID1,
DATA_JAR));
_connectorRepository.addConnectionInfo(IMPORT, new ImportDumpConnectionInfo(DATA_JAR));
...
// Export data to JAR
new DefaultTableCopyTool(_connectorRepository).copyTables(CONNECTOR_ID1, EXPORT);
...
// Import data from JAR
new DefaultTableCopyTool(_connectorRepository).copyTables(IMPORT, CONNECTOR_ID2);
Mass data production: During development you will probably generate some test data. Now you want to go public, but before you'd like to prove your system can handle much more data
than the few items of your test data.
This examples shows how to duplicate the data multiply in the data base and how to alter some of it to get some distinction. The main problem is the correct
handling of primary keys. In this example we simply look for the maximum ID in each table and use that as an offset for new IDs. Of course tables with foreign key
need to be updated, too.
During multiplication we also alter some of the data, i.e. we change all user names.
public class MassDataProducerTest extends AbstractGuttenBaseTest {
private static final int MAX_LOOP = 5;
public static final String SOURCE = "SOURCE";
public static final String TARGET = "TARGET";
private final ColumnDataMapper _nameDataMapper = new ColumnDataMapper() {
public boolean isApplicable(final ColumnMetaData sourceColumnMetaData,
final ColumnMetaData targetColumnMetaData) throws SQLException {
return sourceColumnMetaData.getColumnName().toUpperCase().endsWith("NAME");
}
public Object map(final ColumnMetaData sourceColumnMetaData,
final ColumnMetaData targetColumnMetaData, final Object value)
throws SQLException {
return value + "_" + _loopCounter;
}
};
private final ColumnDataMapper _idDataMapper = new ColumnDataMapper() {
public boolean isApplicable(final ColumnMetaData sourceColumnMetaData,
final ColumnMetaData targetColumnMetaData) throws SQLException {
return sourceColumnMetaData.getColumnName().toUpperCase().endsWith("ID");
}
public Object map(final ColumnMetaData sourceColumnMetaData,
final ColumnMetaData targetColumnMetaData, final Object value)
throws SQLException {
return ((Long) value) + getOffset(sourceColumnMetaData);
}
};
private final Map<TableMetaData, Long> _maxTableIds = new HashMap<TableMetaData, Long>();
private int _loopCounter;
@Before
public void setup() throws Exception {
_connectorRepository.addConnectionInfo(SOURCE, new TestDerbyConnectionInfo());
_connectorRepository.addConnectionInfo(TARGET, new TestH2ConnectionInfo());
new ScriptExecutorTool(_connectorRepository).executeFileScript(SOURCE, "/ddl/tables.sql");
new ScriptExecutorTool(_connectorRepository).executeFileScript(TARGET, "/ddl/tables.sql");
new ScriptExecutorTool(_connectorRepository).executeFileScript(SOURCE, false, false,
"/data/test-data.sql");
_connectorRepository.addConnectorHint(TARGET, new DefaultColumnDataMapperProviderHint() {
@Override
protected void addMappings(final DefaultColumnDataMapperProvider columnDataMapperFactory) {
super.addMappings(columnDataMapperFactory);
columnDataMapperFactory.addMapping(ColumnType.CLASS_STRING, ColumnType.CLASS_STRING,
_nameDataMapper);
columnDataMapperFactory.addMapping(ColumnType.CLASS_LONG, ColumnType.CLASS_LONG,
_idDataMapper);
}
});
computeMaximumIds();
}
@Test
public void testDataDuplicates() throws Exception {
for (_loopCounter = 0; _loopCounter < MAX_LOOP; _loopCounter++) {
new DefaultTableCopyTool(_connectorRepository).copyTables(SOURCE, TARGET);
}
final List<Map<String, Object>> listUserTable = new ScriptExecutorTool(
_connectorRepository).executeQuery(TARGET,
"SELECT DISTINCT ID, USERNAME, NAME, PASSWORD FROM FOO_USER ORDER BY ID");
assertEquals(5 * MAX_LOOP, listUserTable.size());
final List<Map<String, Object>> listUserCompanyTable = new ScriptExecutorTool(
_connectorRepository).executeQuery(TARGET,
"SELECT DISTINCT USER_ID, ASSIGNED_COMPANY_ID FROM FOO_USER_COMPANY ORDER BY USER_ID");
assertEquals(3 * MAX_LOOP, listUserCompanyTable.size());
}
private long getOffset(final ColumnMetaData sourceColumnMetaData) {
ColumnMetaData idColumnMetaData = sourceColumnMetaData.getReferencedColumn();
if (idColumnMetaData == null) {
idColumnMetaData = sourceColumnMetaData;
}
final TableMetaData tableMetaData = idColumnMetaData.getTableMetaData();
final Long maxId = _maxTableIds.get(tableMetaData);
assertNotNull(sourceColumnMetaData + ":" + tableMetaData, maxId);
return _loopCounter * maxId;
}
private void computeMaximumIds() throws SQLException {
final List<TableMetaData> tables = _connectorRepository
.getDatabaseMetaData(SOURCE).getTableMetaData();
final EntityTableChecker entityTableChecker = _connectorRepository
.getConnectorHint(SOURCE, EntityTableChecker.class).getValue();
final MinMaxIdSelectorTool minMaxIdSelectorTool =
new MinMaxIdSelectorTool(_connectorRepository);
for (final TableMetaData tableMetaData : tables) {
if (entityTableChecker.isEntityTable(tableMetaData)) {
minMaxIdSelectorTool.computeMinMax(SOURCE, tableMetaData);
_maxTableIds.put(tableMetaData, minMaxIdSelectorTool.getMaxValue());
}
}
}
}
Changing BIGINT primary keys to UUIDs:
The main problem here is that the foreign key columns referencing the alterered IDs need to be updated, too. Another problem is to get a mapping
between the old number value and the UUID. We chose a pretty simple approach here which simply takes hash code of the names of the table and the ID column
as the base for generating a UUID. It works well, however.
First we define a column data mapper:
public class UUIDColumnDataMapper
implements ColumnDataMapper {
public Object map(final ColumnMetaData sourceColumnMetaData,
final ColumnMetaData targetColumnMetaData, final Object value) {
final Number number = (Number) value;
if (number != null) {
final long id = number.longValue();
final ColumnMetaData referencedColumn = sourceColumnMetaData.getReferencedColumn();
String uuid;
if (referencedColumn != null) {
uuid = createKey(referencedColumn, id);
} else {
uuid = createKey(sourceColumnMetaData, id);
}
return uuid;
} else {
return null;
}
}
public boolean isApplicable(final ColumnMetaData sourceColumnMetaData,
final ColumnMetaData targetColumnMetaData) throws SQLException {
final String sourceColumnName = sourceColumnMetaData.getColumnName().toUpperCase();
final String targetColumnName = targetColumnMetaData.getColumnName().toUpperCase();
return sourceColumnName.equals(targetColumnName) && sourceColumnName.endsWith("ID");
}
private String createKey(final ColumnMetaData columnMetaData, final long id) {
final String key = columnMetaData.getTableMetaData().getTableName()
+ ":" + columnMetaData.getColumnName();
final UUID uuid = new UUID(key.hashCode(), id);
return uuid.toString();
}
}
Then we only have to register the data mapper. The rest will be done automatically by the usual DefaultTableCopyTool:
final UUIDColumnDataMapper columnDataMapper =
new UUIDColumnDataMapper();
_connectorRepository.addConnectorHint(TARGET, new DefaultColumnDataMapperProviderHint() {
protected void addMappings(final DefaultColumnDataMapperProvider columnDataMapperFactory) {
super.addMappings(columnDataMapperFactory);
columnDataMapperFactory.addMapping(ColumnType.CLASS_LONG, ColumnType.CLASS_STRING,
columnDataMapper);
columnDataMapperFactory.addMapping(ColumnType.CLASS_BIGDECIMAL, ColumnType.CLASS_STRING,
columnDataMapper);
}});